

When we started building the new Metigy website as part of our recent rebrand, we laid out a couple of requirements, the main one of which was it had to be fast and scalable. This article focuses on the backend of the website and how we delivered the objective very effectively, using WordPress. Our marketing efforts have responded very positively to everything we put into the new site. Now, before I continue, a few people will grumble with me about the WordPress blog system not being the best. It does have its problems and I’ve managed to hit a very large number of them. Face first, whilst on fire, tumbling off a cliff and being chased by angry cats with knives. But that’s another story. We were aiming to make this site super lean and easy to update via continuous deployment tools like Elastic Beanstalk. Be completely self-contained where possible. But we still want leverage the advantages of WordPress as its admin tool. There are many projects out there that try and solve this problem and I looked at them and learned from their ideas. What we ended up with a fairly simple stack (obviously this is a simplified version of the simplified stack). And our own design, that works for us.
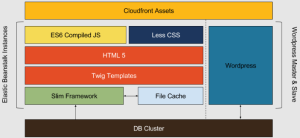
The Technology and Libraries we used
- WordPress – Yes, it’s still there but it’s just an admin tool, handling content creation, asset handling, and uploading. We did write a plugin to add our own custom post types for sections like Careers and Help as well as a few other bits and pieces. What we didn’t do was use their core code as originally intended as it was just too slow for us.
- Slim Framework – My favorite small framework. Gives you enough to get started, is built on PSR7 HTTP Interfaces, and uses the fantastic, lightweight routing library, FastRoute. We combine that with mature libraries such as Monolog for logging.
- Twig – Love this for the templating engine! So powerful and easy to write. Make things a lot easier to write and maintain. Sidenote: There are libraries like Timber designed to let you use Twig with WordPress. I’d recommend trying it!
- Stash – A great caching library for PHP that supports most of the major caching types including Memcache, Redis, and the file system.
- CloudFront – When you’re on Amazon, it’s the best choice (although this may change in the future).
- Elastic Beanstalk – Brilliant for simplifying deployment to multiple boxes
- Composer – Couldn’t not include this as it’s a lifesaver most of the time, handling our dependencies and autoloading efficiently.
How did we make it all work?

The long and the short of it is that we started by figuring out what we wanted from the database and writing those queries. It involved a series of joins and group_concats which meant we could run queries in a fraction of a second. Once we have the data, we run a series of transformations over the results that pre-generate most of what we need for output. This includes the URL – generated using named routes in FastRoute, the author’s details, Images including fallbacks if no featured image is defined, etc. Also to make finding things quick given that we only usually access posts using an id, slug, or similar, we create an index of the indexes for those in the cache too. This gives us really quick lookups for all common searches. By doing that everything is ready for the front-end Twig templates and consistent components that can all be re-used. All the Twig has to handle is deciding what the start and end rows are and if it needs to show the back and forward buttons.
Handling changes from WordPress

Here we wrestled with a few different approaches, some we like more than others:
- Get WordPress to call an API on the site to tell it when something changes. We decided against this on the grounds that it wouldn’t work when we have multiple sites running.
- Get the website servers to call the WordPress API and pull down changes. We decided against this idea as we wanted to make it super lean, and having X number of web servers suddenly poll the WordPress API worried us.
- Run a cron job on each box that checks for changes. This way each website is completely self-contained, bar the need to talk to the database servers. But our caching means that as long as the cache is primed, that won’t matter (and we can use a long expiry time).
We went with the last one because all we needed to do was run 3 simple queries to look for changes and then cache the result.
- Each Post Type last updated time
- The last user updated time (we had to add this via our custom plugin to store custom meta each time the user changed – can’t believe this isn’t built-in)
- Get the last updated time for taxonomies. Again, we manually added this via our plugin.
We then compare that to a cached version and for any changes, we prime the cache for that type as highlighted above.
Are there likely to be any issues?

The short answer is not that we can think of. The main hurdle might be when we have to handle very large numbers of articles. At that point, we might look to migrate to a local SQLite or Redis solution for the stack. A search system could be a problem, but again there are so many ways around that. In those instances, we can query the Database directly with prepared statements, obviously – and cache the search result. The other potential risk is WordPress failing. There are a number of ways this could happen but all are minimal risk thanks to the long-term file cache and separated Database.
The result

We delivered a website in a couple of weeks that’s totally data-driven, fast, easy to scale, and easy to manage and extend in the future. This is really valuable in creating a key asset in a contemporary sales funnel because it means you can deliver, test, and iterate on the design, really rapidly. It has really helped our marketing efforts and we have seen the conversion rates on the new site increase 50-fold. In addition, all of the code is written so that it can be extended and news types added easily. And if we want, the code can be ported to other sites with ease. Our speed tests all score highly and we’ve managed to add a few updates to the site really quickly. We’re pretty stoked with version 1. o of the Metigy website and are looking forward to rolling out more updates soon. It also made it super easy for us to use the amazing Google Optimize toolset to run continual A/B experiments and rapidly adjust the designs based on the outcomes.
And another thing
We’ve learned a lot about how to stay on top of our systems in the last few years. A big part of this has been the monitoring solutions. Our favourite is Sentry which provides APIs for PHP and JavaScript amongst others. The logging they provide is superb, especially on the client side! Highly, highly recommended.







